
I thought I would show people how solving for unknown DNA works by using an example. Whether it’s for cases involving adoptees, unidentified human remains (UHR) or crime scene DNA, the process is pretty much the same. With adoptees, you have the benefit of using any site for DNA, including Ancestry, but with UHRs or crime scene DNA you are limited to uploading to FTDNA and Gedmatch. I am going to use myself as an example, but I have to anonymize my matches for privacy reasons, and I’m only going to use Gedmatch.
The first step is getting a 1 to many match list. The top match, Sally, shares 478.8cM, which is fantastic! In fact the top 10 matches are over or near 100cM, which is what you’d like to see when solving an unknown persons case. See my post on Centimorgans and Segments if you’re not familiar with how DNA is measured. Ideally, you’d like to have at least one match over 200cM, which is in the second cousin range. Once you start getting to around 100cM, you’re usually in the third cousin range, and around 50cM is in the fourth cousin range. 30 cM can be anywhere from third cousin to eighth cousin or more! The more distant the match(es), the harder it is to solve a case. That’s because the further out you go, the more cousins you have! I have 4 siblings, so if I had a sibling match, I know I am one of 3 people. I have 14 first cousins, which means if I had a first cousin match, I would be one of 13 people. I don’t know how many second cousins I have (100?), but a second cousin match is preferable to a third cousin match, and I may have thousands of fourth cousins to sift through to find myself!
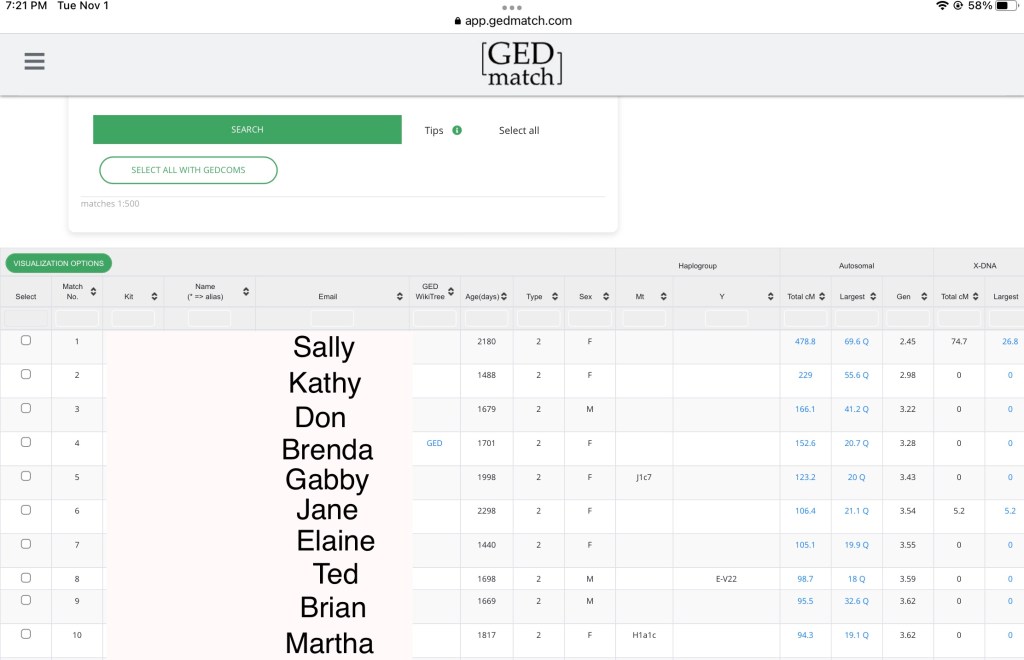
How is Sally related to me? My first thought is 1C1R, or maybe even a 2C. However, my best bet is to head over to one of my favourite tools, the DNA Painter sharedcM project. You can see that there are a lot of relationships for this amount of shared DNA, the most likely being Great-Great-Aunt, Half Great-Aunt, Half 1C, 1C1R, Half-Great-Niece, and Great-Great-Niece. It’s important to remember that all the relationships listed are possible, and even though a relationship is more likely, it doesn’t mean that is what the relationship will be. I like to run this for all of my top matches to give myself an idea of what I’m working with.

The next step I usually like to do is run a clustering tool. If you have a Tier 1 Gedmatch subscription, you can run clustering with Gedmatch. I’ve already talked about my experience with clustering, which you can read about here. Here is where we run into our first problem and we realized this case may not be so easy to solve after all. The big orange square is to genetic genealogists what the blue screen is to anyone who works with computers. Endogamy. This means that the DNA belongs to someone from a population that has intermarried for many years. This causes the DNA shared with matches to be inflated, as I wrote about in my post What is a Cousin.
Clustering is important because you want to be able to sort matches into groups and figure out how the people in those groups are related to each other. It’s a lot like putting together a jigsaw puzzle, like I wrote about in this post. Jigsaw puzzles that have pieces that are all the same colour are very, very hard to put together. However, there’s a workaround! We’re going to do a matrix to see how the top 10 matches are related to each other.
To do a matrix, we select at least 3 matches and click on “visualization options.”
Then we click on Matrices, and select A-Matrix.

We get this lovely matrix with 10 people, almost all of whom are related to each other (yay endogamy!). However, we can see that Sally is not part of the endogamous cluster, and that she is very closely related to Don. Phew!
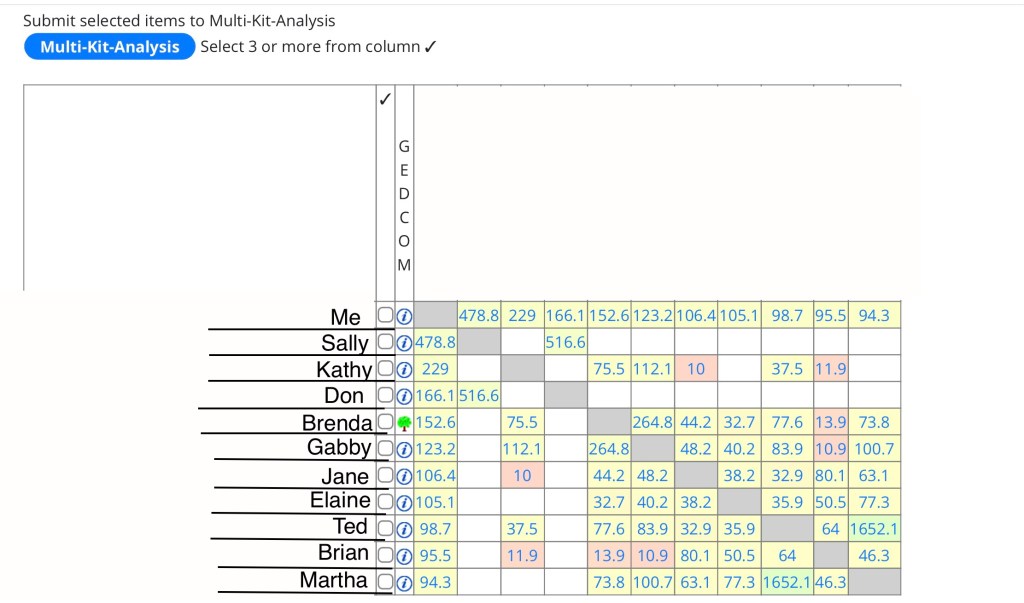
Next we want to build a tree for Sally and Don to see how they are related to each other. Ideally, you’d have a tree to work from, but as you can see in the above matrix, only Brenda has a tree. This means we’ve got some investigative legwork to do. For my own personal genealogy, I don’t mind emailing matches to see if they can give me tree information, but when working unknown persons cases (including adoptees), there’s more of a reluctance. You definitely don’t want to alert someone that their family member has a child unknown to the family (adoptees), is dead (UHR) or is a suspect in a case (crime scene DNA)! For cases in the US, I recommend using a service like BeenVerified or Spokeo. Even non US based emails may come up in BeenVerified and link to Facebook or other social media accounts. You can also use Google to search for the email address. Try using the first part of the email (before the @) to search for usernames, especially in Ancestry member search. Sometimes you can easily find their family tree this way! There are lots of other helpful hints in this video!

Since everything you do after this point is based on your findings, you really need to be sure that the person you find is actually your DNA match. If you try to build out trees for people who aren’t your DNA match, you will not be able to find the connections between the DNA matches. Sites like BeenVerified can conflate similarly named people, or point you to a social media account for the wrong person. Further, the email given on Gedmatch may not belong to the match, but to the person who manages that kit. Both Sally and Don share the same email address, which is my email address. Even if you found my tree, (which anyone with my email address should be able to do), you may not be able to figure out who Sally and Don are in my tree. One important thing to do is to go to user lookup on the Gedmatch home page.

There you can input the match’s email and see how many other kits link to that email. It’s also possible that one of the kits is connected to a tree. If there are a lot of kits, sometimes it can be helpful to input all the kit numbers into a matrix and see if you can figure out if/how they’re related.
Another thing I like to do to analyze my top matches is to click on their kit number, which will take me to their 1 to many match list. This can have important clues, like if their top match is unrelated to your kit. Sometimes their top match will have a tree which can also help you figure out who your match is.
In my case it might be difficult to figure out who Don and Sally are, but let’s pretend like we were able to figure that out. It turns out that Don is the son of Sally’s cousin John. They have the most recent common ancestor (MRCA) of Arthur and Eleanor. Finding an MRCA is really helpful, since we know that I am now also likely to be a descendant of Arthur and Eleanor. Now we can turn to another one of my favourite tools, DNA Painter’s WATO. I wrote a basic tutorial for WATO here.
You want to put in as much detail as possible for WATO, including birth/death years, otherwise it will come up with suggestions that make sense numbers-wise, but not genealogy wise. You will also need to come up with a date of birth for your target person, even if it’s just a guess. Since I know my date of birth, and I know I am much younger than Sally and Don, it can help me narrow down where I fit in this. I am not the most likely hypothesis!

My next step would be to see if there are kits that match Sally and me but not Don, and I would do that by looking at “People who match both kits, or 1 of 2 kits” (blog post on that here). Doing this, I would be able to figure out that there are kits that match Sally and I but do not match Don. Further research shows that they share ancestry with Sally’s mother, which means that I have narrowed down the tree further to descendants of Hugo. While this paragraph is very short, there’s a lot of work that goes into figuring out the trees of those other matches, connecting those trees, and working out Sally’s maternal line. It’s also possible that I’m only related to Sally in one way, and it’s Don I that share multiple connections, or that I’m only related to Sally and Don through Arthur, in which case I would proceed to other matches.
I will do the same thing for the other matches as I did for Sally and Don. The other highest matches, however, are part of an endogamous cluster, so even if you can figure out how they’re related to each other, it’s likely they’re related in more than one way (this means WATO is not a tool you can use). You’d spend a lot of time working on the second top match, who shares a second cousin range amount of DNA, but hopefully you’d notice sooner rather than later that her tree doesn’t fit into the tree with the other matches (I still don’t know how I’m related to her). Such is the life of a person who works with unknown DNA — many of the people are in Gedmatch because they also have genealogical mysteries to solve.
If I go back to my matrix, Brenda, the match that has a tree, is likely a second cousin to Gabby. I spent some time looking for Gabby’s tree using the methods detailed above but came up with nothing. If it were my only choice, I would keep pushing in that direction but since I know that I am looking for a descendant of Hugo, it will likely be faster to build down Hugo’s tree, especially since I know that Hugo only had 3 children.
One of the things you might notice about the names of the DNA matches in this endogamous cluster is that they’re all Mennonite, which can be helpful. If you built down Hugo’s tree you would find the person who married someone Mennonite (if you could recognize a Mennonite surname if you saw one). You would easily find an obituary that would give you a name of this Mennonite person, and then confirm that the DNA matches fit into that person’s tree (at least the ones you could find trees for). The cool thing about Mennonites is that we have our own genealogical subscription website, GRANDMA online, where everyone in the system is assigned a number, and all you have to do to pull up their tree is know their number. Many of my DNA matches have helpfully provided their number in their username. Not so useful for the average genealogical researcher, but invaluable for those with Mennonite ancestry.
My parents are a really good example of what’s called a union couple. They join together two different groups of DNA matches. Thankfully my parents are connected to each other, and mentioned together in a few obituaries, because in the case of an adoptee, I wouldn’t be able to make the connection to find myself using just Gedmatch matches.
If I were a UHR, I am one of three daughters of my parents. Through a description of me (hopefully I was more than just bones!) you might be able to distinguish me from my sisters, or perhaps someone talked about how I was missing or there was a newspaper article about how I went missing which would identify me specifically. Otherwise we have three candidates, and the agency can do further research, including speaking to the family and asking for DNA samples to confirm.
If you really want to help identify adoptees, UHR, or crime scene DNA, please upload your DNA to Gedmatch! If you want to help identify UHR but not crime scene DNA, you can choose to opt out of crime scene DNA matching. Don’t forget to attach a tree!
I hope this overview was helpful. Since every case is different, it’s not always straightforward how to proceed, but the basics of figuring out your matches and building trees is the same in every case.

Leave a reply to Forensic Investigative Genetic Genealogy (FIGG) Education and Certification | Jennealogie Cancel reply